


Also known as point anomalies, global anomalies exist outside the entirety of a dataset. They are the data points that deviate the most from other data within a given dataset.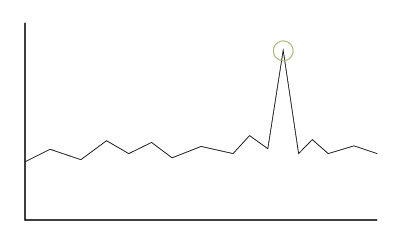
For example, if a control chart displays a data point outside the specified range, this can be considered a global anomaly.
Also known as conditional anomalies, these anomalies differ greatly from other data within the same dataset, based on a specific context or unique condition.
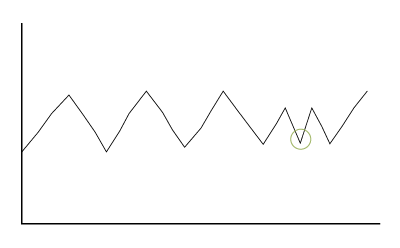
An example of a contextual anomaly can be illustrated on a series of temperature readings collected over time that follow a predictable pattern. A machine alternately heats up and cools in a cyclical manner as it operates. If the machine cools when it is expected to heat, this represents an anomaly, even though the unexpected cooling falls within the expected range of overall temperature.
Data points that deviate significantly from the rest of the dataset. On their own they are not necessarily outliers but combined with another time series dataset they collectively act like anomalies.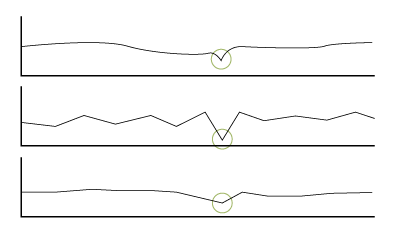
Collective anomalies can be more challenging to spot, since they require comparing similar points across different datasets. An example of when a collective anomaly could be found it the comparison of power supply data for different machines. If the power for the whole plant were to falter, a dip would be seen across all machine data at the same time. This finding would clearly indicate an issue with the central power supply, as opposed to a specific machine.