MLOps: the machine learning assembly line
Last updated on August 26th, 2022
The introduction of assembly lines at Ford Motor Company in the early 20th century was a major milestone in the second industrial revolution. Ford wasn’t making a new product—automobiles had been around for well over a hundred years by that point. Instead, it was making an existing product in a new way. As a result, the company saw orders-of-magnitude increases in production efficiency, and the automotive industry entered the age of mass production.
There’s another practice that’s following a similar trajectory in data science today: MLOps. A portmanteau of two abbreviations (‘ML’ for ‘machine learning’ and ‘Ops’ for ‘operations’), the concept is akin to DevOps, i.e., a pipeline from developer to product. As with assembly lines, the goal of MLOps isn’t making something new; it’s making something better.
MLOps vs. DevOps
In order to understand MLOps, we need to understand where it came from and what makes it different. Given the overlaps between machine learning and software development, one might wonder why we need a separate category just for ML, especially since most companies have already embraced DevOps. Conversely, one might wonder if every business function should have an ops extension.
What’s so special about machine learning?

If you think about how developers write software, they’re working from a set of requirements (or conjuring it from the void, depending on whom you talk to), building, testing and then shipping a final product. The key difference with machine learning is data: ML models require training, and it’s crucial to keep track of the data on which models are trained. In other words, while DevOps focuses on versions of software, MLOps focuses on versions of code, data, and the ML model itself.
Where things get really interesting is in applying machine learning to a DevOps pipeline for delivering software, which is producing data, which can then be used in a pipeline for delivering ML models.
But let’s not get ahead of ourselves.
Getting Started with MLOps
While the goal of MLOps is deploying machine learning models to production, getting there takes a lot of work. Models go through multiple iterations in the form of experiments, with data scientists training them on one set of data and testing them on others. Without a set of practices to keep track of the data, the models and the software used to build and train them, the risk of errors runs high.
- How do you avoid introducing bias into your model during training?
- How do you ensure that everyone is working with the same versions of software tools?
- How do you know the model deployed to production is identical with the one you trained?
MLOps is the answer. Of course, knowing the answer and getting people to accept it are two very different things—just try playing Trivial Pursuit at a bar with no Internet connectivity during Happy Hour.
Part of the impetus behind DevOps was to ease the tension between those working in development and those in operations, since the incentives of the two groups are typically opposed. Developers want the product or update out as soon as possible, but operations wants to keep everything stable, so they’re naturally hesitant to deploy it.
DevOps was the compromise.
Similar tensions exist today between data scientists and engineers, hence the call for MLOps. The way data scientists typically work is very exploratory. They approach a problem like a scientist: forming hypotheses and testing them with experiments. As a result, they tend to be very organized but also idiosyncratic in their organization (not to mention opinionated). That can lead to a lot of confusion when the data scientists throw their ML models over the wall to the engineers.
You could try to enforce MLOps—lock things down, develop branches so that only certain people can merge—but a better approach is to develop the tools that make it easier for data scientists and engineers to collaborate.
Essentially, we need a GitHub for machine learning models.
From DevOps to MLOps
Looking at the tools that made DevOps what it is today, it’s easy enough to envision a similar pattern occurring in MLOps: we start with a plethora of overlapping options, some of which become dominant to the point of standardization. Docker, for example, emerged as the de facto standard for containerization, but it certainly isn’t the only option.

In any case, the entire DevOps pipeline has essentially become standardized across the software industry. The specifics of implementation may differ, but they’re all based around very similar technologies.
The same story is playing out with machine learning: right now, there’s a Cambrian Explosion of tools but few of them actually solve the problems they’re meant to, and most are a real pain to use. Hence, even if you happen to get enough machine learning tools in the right combination, you’ll still have to put up with the hassle of using them. A robust ML development ecosystem isn’t going to spring up overnight, so until it does, early developers will either have to make do with the tools available or build their own.
Fortunately, it seems likely that the adoption of MLOps will proceed much faster than for DevOps, simply because we’ve already gone through a similar process and we know what a good outcome looks like. Of course, the technology is much more complicated this time around, which means the supporting ecosystem will need to be as well.
The Machine Learning Assembly Line
The benefits of MLOps today mirror those of assembly lines a century ago. Having a set of MLOps practices in place improves the product by making testing more rigorous and robust, and it makes development faster via automation. The same is true for assembly lines, especially contrasted with the craft production that pre-dated them. Think of all the quality issues that come with craftsmen making individual parts independently, then trying to fit them together into a final product by making cut-and-try changes.
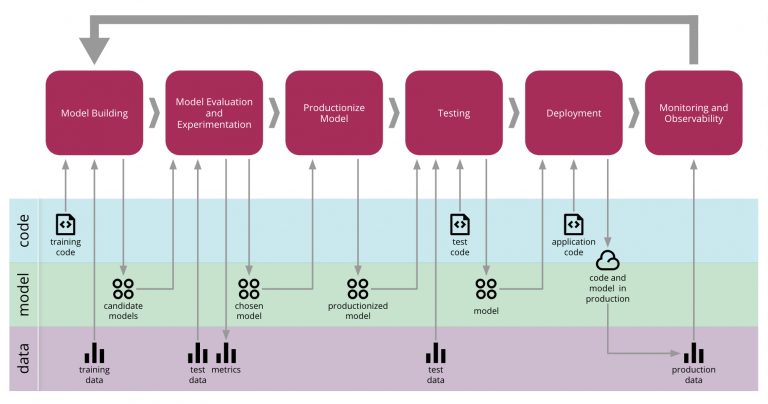
Image courtesy of Martin Fowler.
The benefits of MLOps today mirror those of assembly lines a century ago. Having a set of MLOps practices in place improves the product by making testing more rigorous and robust, and it makes development faster via automation. The same is true for assembly lines, especially contrasted with the craft production that pre-dated them. Think of all the quality issues that come with craftsmen making individual parts independently, then trying to fit them together into a final product by making cut-and-try changes.
Whether you’re building machine learning models or transmissions, the fewer manual tasks there are in your process, the fewer opportunities there are for someone to make a mistake that gets carried down the line.
In data science as in manufacturing: the more standardization, the better.
Share on social: