


Articles
How much manufacturing data do I need?
December 12, 2022
Introduction
Automotive manufacturing facilities generate vast amounts of data, but how much is needed for effective quality analysis? In this post, we explore the key factors that determine the right data for predictive quality tools and how manufacturers can ensure they’re collecting the data that will drive improvements.

Modern automotive manufacturing facilities collect plenty of data by design, especially those that include complex operations and precision manufacturing. Data related to part quality is generated from machine sensors on equipment and at the rate of production in today’s facilities, hundreds of gigabytes of data could be produced per minute.
Since so much data is already being collected, performing manufacturing data analysis with predictive quality tools can be straightforward. These tools use advanced analytics (often driven by machine learning and artificial intelligence) which require a certain amount of data in order to find statistically significant relationships between signals.
Many automotive manufacturers are already producing enough data to run advanced analytics on their operations but not all OEMs and Tier-1s are collecting enough usable data, or the right kinds of data to effectively solve manufacturing problems.
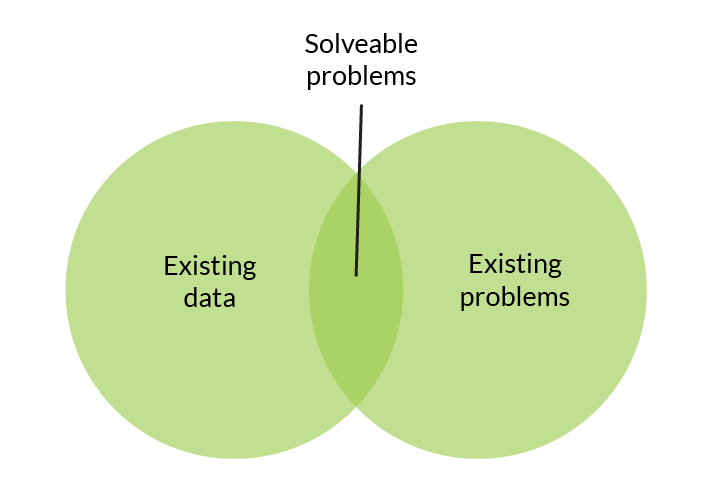
Big data in automotive manufacturing
Not all manufacturing facilities create the same amount of data. We believe that precision manufacturers who produce complex parts and generate a lot of data during part production can benefit the most from using a predictive quality analytics solution driven by machine learning and artificial intelligence.
- The data is already collected in precision manufacturing by the types of machines and robots used. It may as well be leveraged even more to become even more useful.
- Profit margins are so small with precision parts that every improvement in part quality can impact the bottom line.
- The complexity of operations equates to a complexity in the potential problems that could arise in the manufacturing process, meaning problems are not easily solved without ML/AI solutions.
- Precision parts tend to already be serialized which means they are also traceable – a key requirement when looking at part analytics.
A question we are often asked from precision manufacturers is, “How much data is needed to solve our quality problems with a part quality tool like LinePulse?”
As we dig into this question, it will become apparent that the answer isn’t quite that simple.
How do we measure the amount of automotive manufacturing data?
The complexity of our question starts with some definitions. We know that the automotive manufacturing data we refer to comes from sensors on the manufacturing line. The manufacturer needs to monitor specific data “signals”.
The “amount” of automotive manufacturing data can be measured in a few ways:
- The number of signals, or columns of data
- The number of instances/parts, or rows of data
- The depth of data, in terms of how detailed or granular the measurements are
- The digital size of the data, expressed in GB
The real amount of data required depends on the use case and the problem intended to be solved with it. It is impossible to put a size measurement in gigabytes on the amount of data needed, since there is so much variation between different manufacturers, the number of signals they need to monitor, and the potential issues they need to solve.
It is actually possible that two manufacturers producing the same type of component will have different signals depending on how they produce the part. Therefore, it is impossible to say, “Engine manufacturing requires ___ amount of data in order to analyze effectively”.
What types of manufacturing data are needed for predictive analysis?
There are three categories of data that need to be available for a predictive quality solution to work.
1. Manufacturing operations data
General product data comes from machine sensors. This data is typically non-time series data, meaning that each data point includes a single measurement, and not a series of data points tracked over time. There is one recording per signal per part produced.
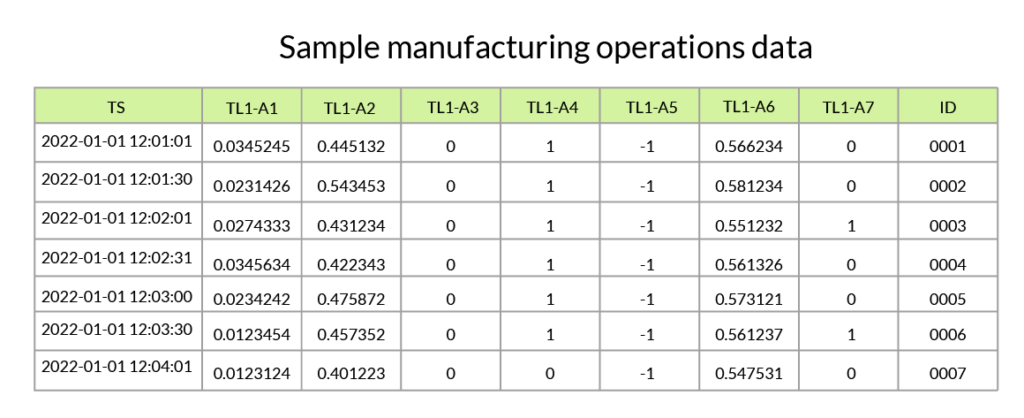
Data collected from these machine sensors can come in a variety of forms, depending on the machine being monitored. These data points may represent measurements such as temperature, weight, torque, speed, or distance. The total collected data across manufacturing will understandably contain a variety of different units.
A less helpful form of general product data is when it is expressed as a binary value, for example, if a distance measurement is not expressed in inches or centimeters, but is recorded as “1” to mean “in range” or “0” to mean “out of range”. Advanced analysis uses incremental measurements to track small changes in sensor data to discover anomalies. If the data does not show enough detail, it becomes very challenging to analyze.
2. End-of-line test data
End-of-line test data is usually time series data. Each signal at the end-of-line test will have a time series trace since the part’s performance is tested over a period of time.
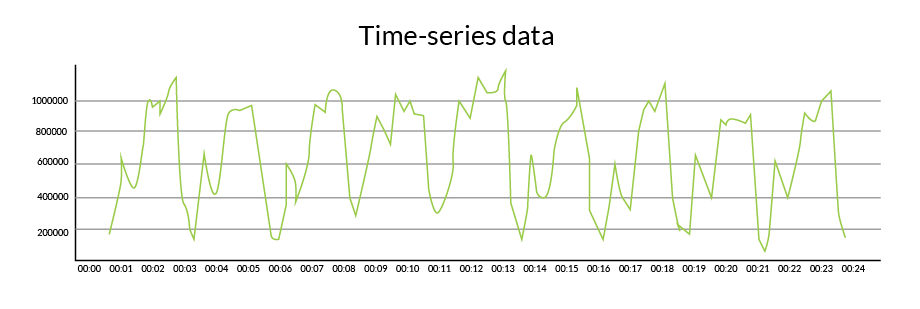
3. Traceability data
Traceability data doesn’t quite fit into the same category as the two other data types since it is a form of metadata. Traceability is necessary to draw conclusions between the manufacturing operations data and end-of-line test data; it determines which part was affected at which stage in the process.
Traceability at the part level is often made possible through serial numbers that are placed on each part.

Each completed part will have a serial number associated with it but sometimes, two or more components are added together during the manufacturing process, and they experience a “part marriage”. When this occurs, the individual serial numbers are combined in some form in the data.
Guidelines for the amount of data needed for preditive quality
There are a few guidelines that can be used to determine if the data collected is “enough” to gain value from by analyzing it with a machine learning algorithim.
Bigger actually is better when it comes to automotive manufacturing data
The more signals producing data across an automotive manufacturing facility, the more opportunities there are to spot trends between them. This in turn increases the potential scope of quality issues that could be resolved.
In a database or data file, the number of rows of data represents the parts produced over time. A manufacturer may refer to “1 month worth of data”, which would be all the data possible to collect during that period, representing all total parts produced. The longer this period, or the more rows of data, the better.
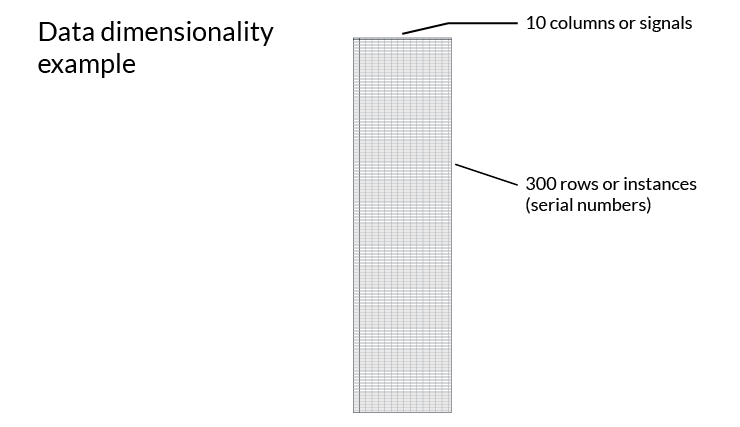
Avoid data dimensionality problems
If the number of signals is much larger than the number of instances, or if the number of columns is much larger than the number of rows in the data, this dataset will not be sufficient to derive value from machine learning. A good rule of thumb is that there should be a ratio of 1 to 30-50. For example, a dataset with 10 signals (columns) would need 300 to 500 instances (rows).
Consider the data granularity equation
In addition to data breadth, the depth of data is also important. The more detailed or granular the data is, the fewer instances you will need to infer a relationship. More granular data enables machine learning models to infer the relationship between signals more easily compared to summary statistic data. Learning this relationship will make machine learning models more insightful about the direct causes of the problem. The more granular the data, the better you can study relationships.
Granularity x number of units = X

Training data for LinePulse
When a manufacturer is interested in LinePulse, we often start by looking at a sample data set to train our machine learning models to find patterns. We recommend 3-4 months’ worth of complete manufacturing data for this exercise to be most effective.
Once LinePulse is trained with this historical customer data, it can begin to process real-time production data. It continues to learn and adapt the longer it is ingesting data.
Setting your facility up for success with data analysis
Aside from gathering the proper amount of data, there are other things that a manufacturer should consider when they are looking to leverage their data with an ML/AI tool.
- The data must have a purpose. Ideally, the data collection strategy is planned in advance with thought given to potential quality risks and types of sensors or recordings that will be necessary to collect to address them.
- The team must understand the purpose of data collection. A team that knows the value of data and understands how it is being used to solve problems will ensure that internal data collection processes are followed.
- The data must be complete. This means that there are no missing recordings in each instance. This can occur if there are any stages on the line where data needs to be entered manually. All signals on the line that are collecting data should be recorded and accessible.
- The data must be traceable. As mentioned above, using serial numbers is a common method to track parts along the assembly line from start to finish.
- There must be a plan for data storage. Often, data is collected but not stored for long enough, nor is there a process to store data properly and securely. The more historical data you have, the better advanced analytics platforms can solve your problems.
- Understand limitations of the data. ML can only solve defined problems that can be described by collected data.
- The data must be accessible. If the data is challenging to access, there is no opportunity to use an ML/AI analytics solution on it. Data can be inaccessible due to technical reasons, or to overly stringent IT security policies.
- Flexibility is required to expand data collection when additional signals are needed. There could be resistance internally or an infrastructure problem that can prevent this from becoming possible.
Providing purpose for your data in automotive manufacturing
It is important to remember that ML/AI is not a magic black box that you can throw anything into to solve an undefined problem. Each application of ML/AI has specific parameters around how it is designed to process data. And more importantly, the data needs to be complete and traceable to get real value from it.
The more intentionality and thought that goes into planning and collecting your manufacturing data, the more fruitful a data analysis process will be. So, the answer to the question about data size is really very dependent on your specific situation. Creating an organizational manufacturing data science strategy is an essential place when starting to find your own answer to “How much data do I need?”.