


Articles
Beyond predictive maintenance
December 12, 2019
Introduction
At Acerta, we often hear our predictive quality analytics mistakenly referred to as predictive maintenance. While related, the two concepts are distinct and play different roles in manufacturing. In this post, we'll explain how predictive quality analytics goes beyond just predicting machine failures, offering a deeper look into operational inefficiencies, scrap rates, and product quality — all while leveraging the power of machine learning. Let's clear up the confusion and explore the real value of predictive analytics in manufacturing.

Have you ever asked an archaeologist about digging up dinosaurs or a civil engineer about driving trains? Even if you’re joking, trust me: they’ve heard it before and it’s not funny.
Frustrating as it is to be misunderstood as an individual, being in that situation as a company isn’t much better. At Acerta, we’ve noticed that our solutions sometimes erroneously end up in the bucket known as ‘predictive maintenance’, which is doubly vexing because, technically, it’s not entirely inaccurate.
A more accurate description is that we offer predictive quality analytics, rather than predictive maintenance. These two concepts are closely linked, but there are important distinctions between them. First and foremost, predictive analytics enables predictive maintenance but not vice versa. There’s much more to it than that, so let’s set the record straight.
Machine learning vs Statistical Process Control
One reason predictive analytics and predictive maintenance are conflated is that they both tend to utilize machine learning. For manufacturing engineers who may be unfamiliar with machine learning and the related concept of neural networks, it may help to contrast these novel tools with one that’s already widely used and well-known: statistical process control (SPC).
Perhaps the biggest advantage of neural networks—and the reason they became popular—is that they can learn nonlinear relationships amongst data points. Statistical processes, including linear and nonlinear regressions, require a specified finite number of relationships between variables. Neural networks, on the other hand, can model complex, nonlinear relationships across various signals and variables.
Think of family resemblance: it’s not about a single trait that everyone in a family shares in common; the similarities between them are much more complicated than that. In some cases, we can’t really say what the family resemblance is, even though we know there is one. Now think of SPC or linear modelling, where you need to know exactly what you’re modelling ahead of time. That’s not to say you can’t amend SPC, but whatever adjustments you make will always be based on supervised concepts.
In contrast, a lot of what we do at Acerta is semi-supervised learning, where we try to understand the normal behavior of a system without knowing the rules for it ahead of time. In SPC, you have minimums and maximums and you’re just trying to keep your averages within tolerances. In our case, we don’t know what the mins and maxes are ahead of time—instead, we’re learning the typical statistical properties of measurements and looking at the linear and nonlinear relationships between them.
Basically, we’re learning what a client’s typical performance looks like based on historical data, and then we look at a new set of data to see if our models can explain it. If they can, we know we’re on the right track. If they can’t, it’s likely that the data was generated by a unit that contains defects (i.e., it’s an anomaly). There’s a related concept in design engineering called ‘generative design’ where the idea is to control the process that produces the dimensions, rather than controlling the dimensions themselves.
We’re doing the same thing, but for quality in manufacturing.
Artificial Intelligence in Manufacturing
One reason that machine learning works well for assessing quality in manufacturing is its ability to handle a large number of variables and an even larger number of relationships between them. In industrial welding applications, for example, you have to take a multi-sensory approach because data from a single sensor cannot tell you anything about the quality of a weld. The same holds true for complex assemblies—the amount of data production processes generate is increasing drastically.
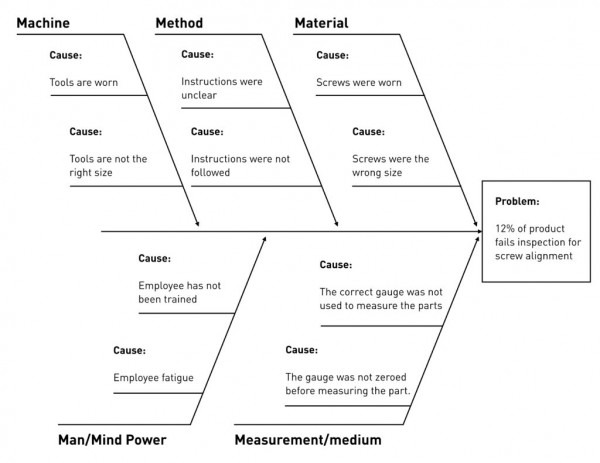
Ishikawa (a.k.a “fishbone”) diagram for visualizing categories of potential causes of a problem.
Compounding that is the issue of experts retiring—people who worked in the same plant for decades and learned all the tricks—and their expertise and experience is being lost. As a result, manufacturers are starting to find themselves squeezed between Big Data on one side and The Skills Gap on the other.
This is why we need to find better ways to approach quality control; manual analysis involving dozens of stations and hundreds of variables just doesn’t cut it when you’re short on experts and relying solely on SPC isn’t enough. It’s not just the number of variables, but the number of connections between those variables.
Think of it this way: the human brain has approximately a hundred billion neurons, each connected to roughly 7,000 others. That works out to about a quadrillion (1015) synapses, which (incidentally) is why creating a human-scale artificial neural network is so difficult. Now, imagine trying to reduce the problem several orders of magnitude by ignoring the synapses. That’s essentially SPC.
To use another analogy, it’s like a doctor trying to assess a patient’s health solely by taking their blood pressure once a day, between 9:04 and 9:05pm. The doctor will get something from that, but they’ll miss a lot more.
Predictive quality analytics vs predictive maintenance
Right now, it’s much easier for people to understand the concept of predictive maintenance: everyone’s had the experience of machines failing on the production line, so the value of being able to predict which machines need to be fixed before they fail is obvious.
Conveying the concept and benefits of predictive analytics is more difficult.
One way to frame it is that it’s all about uncovering inefficiencies, in terms of things like scrap rates, which requires you to collect enough data, early enough in your production process. Unfortunately, a lot of the production engineers we’ve talked to have said that they’re incented to reduce the amount of data they’re collecting from a product the longer they manufacture it.
That reduces the manufacturing cost, but it also means that if you start experiencing issues with products at the end of the line after you reduced the amount of data you’re collecting by 80 percent, you won’t have the clues you need to be proactive and figure out how to fix it. In those cases, there’s a tendency to look at the periphery machinery, but we’ve learned that the best way to get to the root cause of a manufacturing issue is to take a close look at the production process itself; predictive analytics encourages adopting a wider view.
Another way to understand the distinction between predictive analytics and predictive maintenance is that it mirrors the one between two common secondary goals in manufacturing: reducing downtime and increasing first time through yield (FTT). Both serve the primary goal of increasing throughput—if you want to sell more widgets, you can reduce the time your widget-makers aren’t making widgets or the number of defective (i.e., nonsellable) widgets you make. Obviously, manufacturers want to reduce both, but the important point is that it’s predictive analytics which enables you to do that; predictive maintenance really only addresses the first option.
This is illustrated in a recent project with one of our clients, where we separated their data into multiple failure modes, distinguishing between scrap rates and downtime. Ultimately, they wanted our predictive analytics to reduce both, but they’re still separate goals.
Predictive analytics facilitates predictive maintenance, but the latter is just one application of the former. If you want to improve your operational efficiency, predictive maintenance is just one small part, and efficiency isn’t even the whole picture. Product quality is equally important, but even the best predictive maintenance program won’t help with that. With proper implementation for the right application, predictive analytics delivers improvements on efficiency and quality simultaneously.