Machine learning and AI definitions for manufacturing
Last updated on October 11th, 2022
You’ve probably heard many of the terms in this post and maybe you have a sense that they’re important for Industry 4.0. But, do you know what they actually mean? For example, what is machine learning and how does it relate to artificial intelligence (AI)? What’s the difference between machine learning and deep learning?
It’s easy to confuse these terms but there are some important differences, especially for manufacturing. Let’s take a closer look.
Artificial intelligence
When most people think of AI, they think of robots or androids: machines that look and act human. But, AI simply refers to human-like reasoning in computational systems. AI systems are intelligent: they solve the kinds of problems we normally associate with human-level intelligence. Think of speech recognition or the ability to classify items based on a certain set of features.
Machine learning
Machine learning is one kind of AI; it uses algorithms or statistical models to perform a task without explicit instructions. For example, you can use machine learning to differentiate good and bad parts coming off an assembly line without having to tell the program what a good or bad part looks like. This is actually an example of unsupervised machine learning, which we will talk more about below.
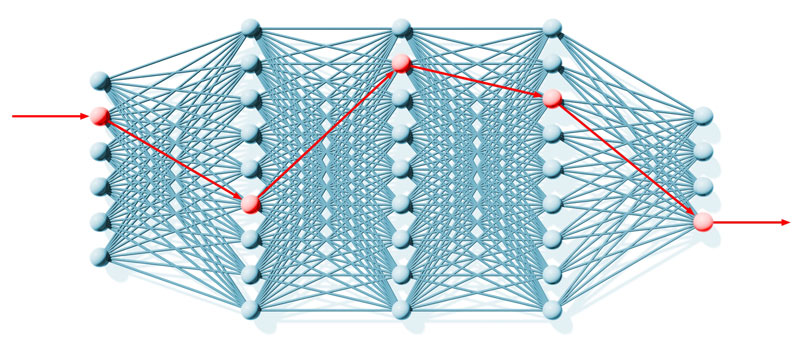
Deep learning
Deep learning is a type of machine learning based on artificial neural networks, which are designed to emulate the way our brains work. Artificial neural networks are made up of nodes connected and structured into input layers that connect to hidden layers and to output layers. The hidden layers are where the deep learning comes from.
Deep learning is probably the most popular approach in machine learning today but it’s not the only approach, just as machine learning is not the only kind of artificial intelligence. The type of AI that works best for manufacturing depends on the problem you’re trying to solve and the data you can use to solve it.
Labeled and unlabeled data
If you want to use machine learning to improve operations, you’re going to need data. In good news, most manufacturers are already collecting and storing a lot of data. In addition to outputs from testing and production, you might also have environmental data, maintenance records, shift schedules, and many other data sources. Each point in your datasets can be thought of as an individual unit described by features.
Think of a spreadsheet. Your data points are like rows and your features are like columns. For example, if you’re looking at the data from an NVH (noise, vibration, and harshness) testing station, those features include frequency and amplitude. When it comes to machine learning, the particular features of a dataset are less important than whether the data is labeled or unlabeled.
- Unlabeled data lacks tags or explanations for what it is. Think of a series of results from an end-of-line test without any indication as to which units passed or failed.
- Labeled data is augmented with a tag or classification, such as pass or fail, which provides additional information.
You can apply machine learning to both labeled and unlabeled data but your approach will differ depending on the type of data you’re dealing with.
Supervised, unsupervised, and semi-supervised learning
The terms supervised learning and unsupervised learning are often used when we talk about machine learning. These learning styles describe different algorithms we can use to solve machine learning problems. The style that you use depends on the data you have and the problem you’re trying to solve. There’s also semi-supervised learning. Here are a few points about each of them.
Supervised learning
The learning approach for labeled data is called supervised learning. It involves presenting a machine learning model with training data and a desired output. For example, you can apply supervised learning to a set of historical testing data, with units labeled as passing or failing, to predict whether units will pass or fail in the future.
Let’s say you want your model to distinguish between defective and non-defective transmissions. By showing the model some historical data, you can teach it what a defective transmission looks like so it can recognize when a new unit is defective. Labels tell the model what counts as defective and non-defective so it can classify new transmissions into one of those two categories. This is an example of a classification problem, where the solutions are qualitative. You can also use supervised learning for regression problems that have numerical solutions, like predicting frequencies for NVH testing.

Unsupervised learning
The approach for dealing with unlabeled data is called unsupervised learning. It involves grouping units together with certain probability densities based on the similarity of their features. You can use unsupervised learning to identify anomalies in production data that result from subtle changes that conventional quality processes may miss, such as tool wear.
Unsupervised models are able to group data points and features without being told what to look for. Although there’s no specific target to predict, the model can map the underlying structure of a dataset. It cannot tell you which units passed or failed at an end-of-line test but it can group those units according to their similarities and separate them by their differences.

Semi-supervised learning
In semi-supervised learning, only one feature is labeled. For example, if you only label engine misfires but no other failure modes, you would only be able to train the model on engines that misfire and classify engines as either misfiring or not.
Clustering and dimensionality reduction
Clustering problems involve grouping data points to detect anomalies in the data. This includes hierarchical methods which group the closest data points together, or density-based methods, such as DBSCAN clustering, which groups high density points together.
Dimensionality reduction combines similar features which makes data easier to process by reducing the number of groups. For example, you might combine the frequency and amplitude of a signal into one group.
In some cases, you can use clustering and dimensionality reduction simultaneously, condensing the number of data points and the number of features at the same time.
Data quality matters more than data quantity
How many data points do you need to apply machine learning in manufacturing? Truthfully, data quality matters more than data quantity, and this is true regardless of whether you’re talking about labeled or unlabeled data, supervised, unsupervised, or semi-supervised learning. And, using the right set of machine learning algorithms is critical to getting the most from your data. This is why it’s important to analyze your manufacturing dataset and your goals before you build any machine learning models.
Ready to get started?
Our LinePulse product performs advanced analytics on your manufacturing data using machine learning and AI to help you accelerate root cause analysis and improve first time yield. Built by engineers for engineers in precision manufacturing, the LinePulse SaaS suite of solutions is forged from industrial experience and driven by data science. It enables companies like yours to turn complex product data into actionable insights that optimize production, improve product quality, and boost the bottom line.
Want to learn more? Get in touch.
Share on social: