
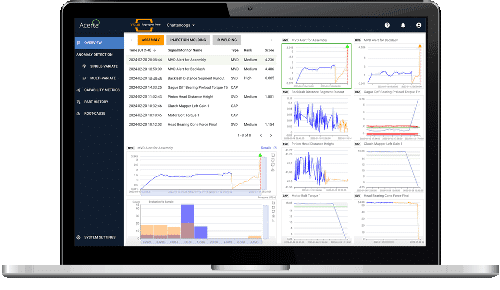
“LinePulse is an important solution in Dana’s digital strategy and helps our manufacturing teams automate overhead, monitor and manage product quality, and optimize productivity. Due to the success of a multi-year engagement with Acerta, we are deploying the next generation of LinePulse in key driveline and e-Propulsion plants.”
“Nissan recognizes the strength in Ontario’s thriving automotive ecosystem combined with expertise in AI and manufacturing. We worked with Acerta to accelerate the development of this new technology for our vehicles to bring future tangible benefits to our customers, and we’re excited to continue our partnership.”
“We are thoroughly impressed with the level of expertise and dedication demonstrated by Acerta in supporting ZF to develop an AI-based road friction estimation module. Thanks to Acerta´s innovative solution, we have significantly improved our ability to predict grip conditions and ensure driver safety.”

